
Our curse — work estimation.
Yep, we try to nail it, but why do we fail so miserably?
estimate — to judge tentatively or approximately the value, worth, or significance of —also, to determine roughly the size, extent, or nature of
Let’s kick it off this way…
The age-old dilemma of time, we try so hard to fill it up, always pondering what and how much can be done, or if it’s even possible. Then there’s the eternal quandary of how to estimate at all, with all those fiery debates — my way is better than yours. But, should we even estimate? Okay, maybe that’s a bit too radical. After all, day by day, it sets our natural cycle, with its 24-hour tenure. Time is, after all, the foundation of all our calculations, plans, decisions. We live on a timeline, and although we can’t control time itself, we can manage what we do with it, or at least try to. But why, oh why, do we mess it up so spectacularly?
The subject has always intrigued and fascinated me. This discrepancy between what we assume (our estimates) and what actually happens (post-factum analysis). Was the estimating flawed, or perhaps the measurement of results was inappropriate, or was there an issue in between? This challenge and finding solutions were what I dealt with daily a few years back; building and leading a team of over 30 people, juggling several projects simultaneously in the pipeline, needing to control the flow so we all delivered what was needed on time, patching gaps (both staffing and timing issues), optimising processes, extinguishing fires — oh, there was always something going on. Surprisingly, in most cases, we succeeded (it was always a team effort), and although work estimation was a part of every day, I am convinced today that our successes had little to do with their accuracy.
So, we’ve got a few pieces of this puzzle. First up is the estimation itself, the second part is everything that happens while working on the estimated items, and of course, there’s the end of the process — which means gathering results, analysing, and possibly optimising. Today, I’ll focus on the middle part, but let’s first briefly touch on the first piece of the puzzle.
Estimate, but how?
The internet is filled with knowledge that can provide answers quickly and painlessly. Two of the most popular methods are:
- Planning Poker
- Magic Estimation
But the method or process itself is secondary — the key element is choosing the right unit, defining the scale, and correlating it with values that everyone can understand. Before we go any further, here are a few common truths:
- we are terrible (we as humans) at estimating time — check Planning fallacy
- the more complex the item, the worse we are with estimation
- moreover, psychological factors and the context occurring during the work estimation process itself are too often ignored: the senior-junior problem, authority, self-confidence, ego, peer pressure
If anyone thinks they’re good at estimating time, I recommend a very simple experiment. If you haven’t already, it’s worth trying — plan your workday in the morning, outlining what you think you’ll accomplish; note down an estimated time for each main activity. Then, throughout the day, in 30–60 minute intervals, do a quick retrospective on how you’ve spent your time — I often also add information about the quality (whatever that means at the moment — but I have additional criteria). In the evening, it’s time for analysis and self-reflection. The results are interesting — I recommend it…

If not “time,” then what? The Agile community found a beautiful solution in replacing time with size or weight. The whole trick is to replace the very abstract value of time with something that is closer to us humans and easier for our senses to grasp. To this, the element of relative sizing was added, which is almost natural for the Homo sapiens species — if anyone has ever observed children, they know what I’m talking about: “My cookie is bigger than yours.”
So, we’ve chosen size… Alright, fantastic!! But what are we measuring? Naturally, it seems we’re measuring the effort required from us to complete a task. Along with this, we have a set of values to choose from, and that’s where Fibonacci comes to the rescue with his sequence — I also recommend reading articles on Practical Fibonacci.

Phew, okay, here’s the whole process in a nutshell:
- We have a list of tasks to complete.
- We pick a task we know is easy, something very simple.
- Then, we choose a task that we see will require some effort, thought, and maybe a consultation with a teammate.
- We assign the value 1 to the simple task.
- And we give the more complex task a value of 8 or 13.
- Any task that seems to be larger than 13 should be broken down into smaller pieces before starting.
- With these two values as references, assessing the rest of the tasks becomes very efficient (small hint: don’t think about time at all, think about how complex the task is, whether it’s less or more complex than the ones you’ve already estimated).
And there’s one more little thing that helps — think about buckets :-)
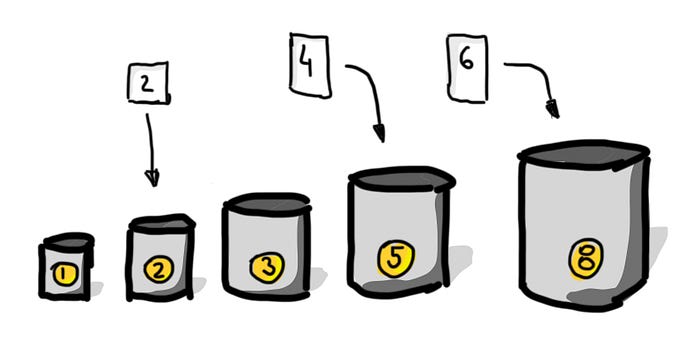
So, even if it seems to you that the estimated work is 6, just a bit more than 5, you need to use a bigger bucket to accommodate it — which means in our case, the final value will be 8. Of course, this approach can sometimes give the impression of overestimation at the level of a single task, but… On one hand, it’s necessary — the larger the task, the larger uncertainty (so extra safety embedded in our estimation)… And perhaps most importantly — we’re not really interested in optimisation at the level of one task, but at the level of the entire feature/project.
And what about time?
This is a classic question, most often coming from the business side: “How long will it take? When will it be delivered?” If you skillfully select your two reference tasks, the ones valued at 1 and the ones at 8 points, you can attempt some calculations. For instance, if you’ve concluded that the project will take 234 points, and you assume that 1 point will take one developer half a day to complete, and you have 3 developers in your team, also assuming that work synchronisation and communication are part of this estimated point, then:
(234 * 0.5) / 3 = 39 days, which is about 2 months.
Everything is fine and wonderful, but in reality, no matter what we do during estimation, no matter how hard we try to be precise — it doesn’t matter in the face of Murphy’s Law.
“Anything that can go wrong will go wrong.”
Probability distribution
Let’s consider a classic real-life example from the old days when commuting to the office was the norm. If we examine the time it takes to get from the office to home after work, assuming we’re using our own transportation — a car. On average, it might take us about an hour, but… there are days when the traffic is lighter, and you make it in 40 minutes. However, there are also days when you get stuck in a traffic jam, and the return trip takes you 1.5 hours; there might also be occasions when you get a flat tire, have a minor accident, and the time extends to 3–4 hours. And finally, perhaps after a work party, you end up staying overnight at the office and only return home the next day — it happens sometimes…
If we wanted to plot this on a graph, it could look as follows:
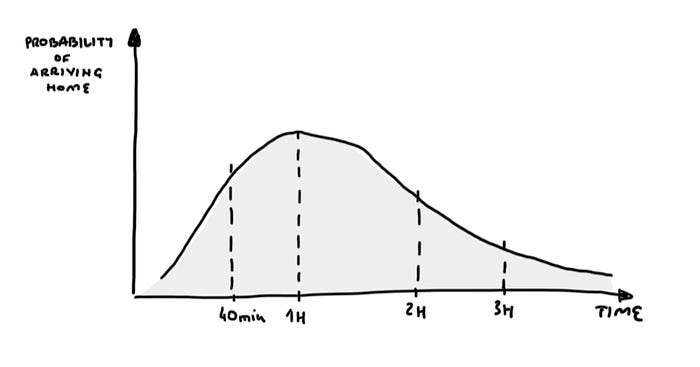
Such a chart is often called a “bell curve,” with the difference that in our case, the chart has a very long tail and practically never reaches zero.
It might seem logical to choose values that are most probable. However, we know all too well that the most probable doesn’t necessarily mean that it will occur in this specific case, right here and right now — the range of possibilities is very broad. And the conflict related to this arises already at the level of estimating itself — the psychological factor associated with the internal need to be considered a reliable person:
- On one hand, we want to estimate in such a way as to have the highest chance of completing the work on time, choosing then above the 80% mark by adding a lot of safety.
- On the other hand, we don’t want to be seen as someone who exaggerates, is less capable, and in this case, we would stick to average values around the 50%.
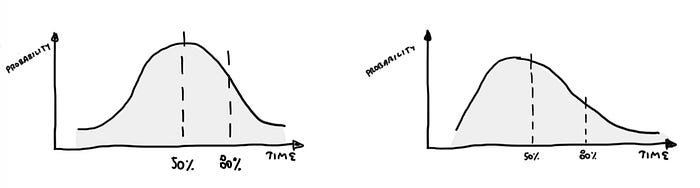
So, on one hand, we have our buckets and sizes, and on the other hand, we have the addition of safety to each task — “just in case”. But as I mentioned earlier, these estimates aren’t really significant at the level of the entire project — of course, they are important, showing us at least the complexity of the entire endeavour, but… What becomes crucial is what actually happens later, that is, in the phase of task implementation itself. And indeed, this element of the whole process is critical when it comes to delivering the project, the entire project, to completion.
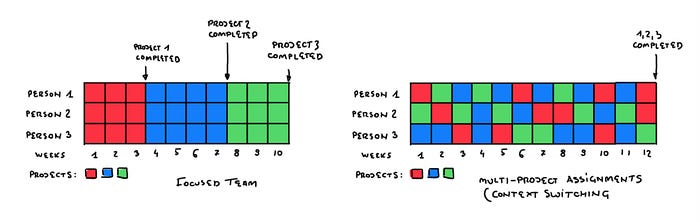
Multitasking — context switching
Not so long ago, belief in multitasking and heroes doing several things at once was quite common. I hope it’s gradually becoming outdated in light of recent research, and there’s no need to convince anyone that there is no multitasking — it’s always context switching — that’s how our brain operates, period. Of course, we’re talking about situations where the same brain network is involved in processing information.
This feature of our biology translates directly into our work and can be one of the reasons for problems in the project as a whole. It’s estimated that jumping from task to task can consume up to 20% of the time. In other words, metaphorically speaking, by doing “two things at once,” you are doing each of them up to 20% slower.
A derivative of this is “The True Cost of Distractions.” Someone calculated it — formula below — but regardless of whether the formula is true or not, we know this phenomenon from our own experience… You’re thinking about something, you’re focused, someone or something interrupts you… When after a short break you try to return to the previously interrupted work, it requires a significant effort from you to get back to the lost level of focus.
True Length of Distraction = Length of Distraction + 23 mins and 15 secs
Student Syndrome
This phenomenon is widespread and unfortunately not limited to students. It’s a form of procrastination. We wait until the last minute to start working on a task. Naturally, this is linked to increased stress levels and often ends with the need to extend the deadline to complete the task. This certainly impacts earlier estimates.
There’s also the flip side. When a task is completed ahead of the planned time, but the person prefers to keep this fact to themselves.
Ok, and the last one for today, the third factor that affects why estimates, no matter how good, usually do not align with reality.
Parkinson’s Law
“Work expands to fill the time available for its completion.”
And when we add the previously mentioned Murphy’s Law to this mix, we know what happens to our estimates.
If there is any continuation of this topic from my side, I’ll describe how we dealt with these and similar problems. Managing buffers, focusing on the global optimum while abandoning the local one, how we solved synchronization issues between people tasks and resources, a bit about the development process itself, etc.
